type
Post
status
Published
date
Mar 1, 2026 04:57
slug
rec-weekly-2026-W09
summary
本周共收录 23 篇推荐系统相关论文,其中 5 分论文 5 篇,4 分 10 篇,3 分 8 篇,整体质量出色。Generative Recommendation(生成式推荐) 是本周最显著的技术主线,6 篇论文直接聚焦于此,涵盖 Semantic ID 编码、受限解码优化、广告场景部署和多任务统一框架。另一条主线是 LLM 与推荐系统的融合范式——"LLM-as-Rec"(LLM 作为推荐骨干)与"LLM-for-Rec"(LLM 辅助推荐)两条路径本周都有重要进展。工业部署论文占比极高(6 篇含 Online A/B 测试),来自 AliExpress、快手、Apple App Store 等一线平台。
tags
推荐系统
周报
论文
category
推荐技术报告
icon
password
priority
本周概览
本周推荐系统领域迎来一个标志性时刻:生成式推荐从学术实验走向多平台工业部署。Google/YouTube 的 STATIC 实现了首个生产级严格约束生成式检索,快手的 GR4AD 全量替代了传统 DLRM 广告检索栈,AliExpress 的 SIGMA(已被 SIGIR 2026 接收)在多任务推荐场景取得 GMV +7.84% 的收益。三大平台几乎同时公开各自的生成式推荐系统,意味着这一范式已从"能否工作"过渡到"如何在不同场景高效工作"的新阶段。
与此同时,LLM 与推荐系统的融合正从理论探索转向务实的工业化路径。Netflix 提出可学习的 verbalization 框架、阿里巴巴用 LLM 生成粗排伪标签缓解曝光偏差、Apple 用微调 LLM 生成搜索相关性标签扩充训练数据——这些工作的共同特点是将 LLM 的能力锁定在离线环节,不增加在线推理开销。这条"离线增强"路径正成为 LLM-for-Rec 的主流工业实践。
本周 23 篇论文中有 11 篇包含线上 A/B 测试验证,覆盖阿里巴巴、快手、Google、Apple、华为、VIVO 等多家平台,工业落地密度之高在近期颇为罕见。
趋势深度分析
生成式推荐的工业化竞赛:从单点验证到系统工程
生成式推荐(Generative Recommendation, GR)的核心理念——将推荐重构为序列到物品的生成任务——自 2023 年 TIGER 在 NeurIPS 提出 RQ-VAE Semantic ID 以来,经历了快速的工业化验证。2024 年 Meta 的 HSTU 以万亿参数规模首次在数十亿用户平台验证了生成式架构的可行性,2025 年快手的 OneRec 和美团的 MTGR 分别在内容推荐和外卖场景完成部署。本周则标志着 GR 进入多场景扩展期——电商、广告、视频三大核心场景同时出现独立的工业系统。
SIGMA 在 AliExpress 的部署值得关注的不仅是 GMV +7.84% 的收益,更在于它的"多任务统一"设计。传统级联系统需要为搜索、推荐、探索、季节性推荐等场景分别维护模型,SIGMA 通过指令驱动的生成框架将七种推荐任务统一到单一模型中。其多视角语义锚定(Multi-View Semantic Grounding)通过搜索日志、视觉特征、世界知识和协同信号四种对齐方式构建统一潜空间,混合 Item Tokenization 则兼顾 SID 前缀的语义泛化能力与唯一 ID token 的细粒度区分力。消融实验显示语义锚定是最关键的组件——移除后 HR@1 从 9.61% 降至 7.80%。从 Qwen3-0.6B 扩展到 Qwen3-4B 时性能持续提升,表明 GR 系统可以受益于 LLM 的 scaling law。该工作已被 SIGIR 2026 接收。
GR4AD 首次将 GR 系统化用于大规模广告场景。广告推荐相比内容推荐有独特挑战:需要平衡广告主价值与用户体验,面临更严格的延迟约束,且冷启动问题更突出(中小广告主)。GR4AD 的 LazyAR 解码器设计颇有巧思——在总共 9 层 Transformer 中,前 6 层不依赖前序 token 条件,可以跨所有解码步骤并行计算,仅后 3 层施加自回归依赖,使得 QPS 近乎翻倍。RSPO(Ranking-Score Policy Optimization)将列表级强化学习引入 GR 训练,以 eCPM 作为奖励信号,通过 Lambda 框架加权和参考可靠性门控优化排序。线上广告收入提升 4.2%、中小广告主投放量增长 17.5%,已在 4 亿用户规模全量部署。值得注意的是,GR4AD 出自快手 Guorui Zhou(周国睿)团队,该团队同期的 DiffGRM(用扩散模型替代自回归解码)已被 WWW 2026 接收,显示快手在生成式推荐方向的系统性投入。
STATIC(Vectorizing the Trie)解决了 GR 工程化的一个关键缺失环节:如何在硬件加速器上高效执行约束解码。传统 Trie 约束解码在 CPU 上需要额外 31.3ms/step(占推理时间的 239%),完全不可用于生产级服务。STATIC 的核心洞察是将前缀树扁平化为 CSR(Compressed Sparse Row)稀疏矩阵,将不规则的树遍历转化为完全向量化的稀疏矩阵运算——延迟开销仅 0.033ms/step(推理时间的 0.25%),实现 948 倍加速。在 YouTube 短视频 Home Feed 上部署后,7 天新鲜视频观看量提升 5.1%,CTR 提升 0.15%,约束合规率 100%。系统基于 30 亿参数的 Gemini 模型,运行在 TPU v6e 上,约束集规模达 2000 万 item。这是首个生产级严格约束生成式检索的部署,Google 已将其开源于 GitHub,发布后迅速获得 MarkTechPost 等多家科技媒体报道。
与此同时,Semantic ID 的设计优化也在加速推进。IntRR 针对 SID 的两个核心痛点提出解决方案:通过递归分配网络(RAN)以 UID 作为协同锚点动态重分配语义权重,对齐索引目标与推荐目标;同时将层次化 SID 的遍历内化为递归过程,每个物品仅消耗 1 个 token,根本性解决了序列长度膨胀问题。在 Amazon Toys 数据集上实现平均 +63.1% 的指标提升,训练吞吐提升 75%,推理延迟降低 2.93 倍。TrieRec 则从另一个角度切入——通过两种位置编码将 Trie 结构信息显式注入 Transformer,在多个数据集和骨干模型上取得平均 8.83% 的提升。何向南团队的 Fine-grained Semantics Integration 提出 SA-Init(语义感知初始化)解决了 SID token embedding 随机初始化切断与预训练语言空间连接的问题。这三项工作共同表明 SID 的设计优化已成为 GR 领域最活跃的研究方向之一。
LLM 融合推荐:离线增强成为工业主流路径
LLM 与推荐系统的融合经历了从"LLM 直接做推荐"到"LLM 辅助推荐系统"的范式演进。早期工作如 P5(2022)和 TALLRec(2023)直接将推荐转化为语言任务,但在工业场景面临推理成本、延迟和规模化的严峻挑战。本周多篇论文表明,业界正收敛到一条更务实的路径:LLM 负责离线的高质量标注、特征增强和知识蒸馏,轻量模型负责在线实时推理。
Generative Pseudo-Labeling(GPL)是这一路径的典型代表。粗排模型仅在曝光交互数据上训练却需对所有召回候选打分,这种训练-服务偏差是工业推荐系统的顽疾。GPL 的创新在于利用微调的 Qwen2.5-0.5B(LoRA rank=8)从用户历史 SID 序列预测未来兴趣锚点,在冻结的多模态语义空间中将锚点与未曝光候选匹配,生成置信度加权的伪标签。三维正交不确定性校准——语义离散度、历史一致性和 LLM 内在置信度——确保了伪标签的质量。全流程完全离线(96 块 H20 GPU 约 6 小时处理一天流量),零在线延迟增加。淘宝粗排阶段 CTR 提升 3.07%,推荐集中度从 70.80% 降至 45.91%(多样性提升超 35%)。值得注意的是,GPL 与 HiSAC 共享多位核心作者(Kun Yuan, Junyu Bi, Daixuan Cheng 等),显示阿里巴巴推荐算法团队在粗排偏差纠正和长序列建模两个方向的系统性投入。
Netflix 的 From Logs to Language 开辟了一条不同但互补的路径。它关注的是 LLM-as-Rec 范式下一个被忽视的关键环节:如何将结构化用户交互日志转化为有效的自然语言输入(verbalization)。现有方法依赖刚性模板简单拼接字段,产出次优表示。该工作提出可学习的 verbalization 框架:用 GRPO 强化学习训练一个 Verbalizer 模型,自动将原始交互历史转化为优化文本。完整流水线(Verbalized + Reasoner 训练)相比模板基线 Recall@1 提升 92.9%,其中 verbalization 本身贡献了 50.1 个百分点的独立价值。大模型(32B)倾向于更高程度的抽象(压缩比 0.27 vs 8B 的 0.42),涌现出噪声过滤、偏好摘要等策略——这标志着从"人工设计 prompt"到"学习最优 prompt"的范式转变。论文来自 Netflix Linas Baltrunas 团队,目前标注为 "work in progress",暗示后续可能有更完整的线上验证。
Apple 的 Scaling Search Relevance 提供了 LLM 作为标注器的工业实践范本。对比实验发现领域特定微调的 3B 模型(F1=0.800)显著优于 10 倍大的预训练 30B 模型(F1=0.382),用该最优 LLM 生成数百万跨语言、跨 storefront 的文本相关性标签,推动 App Store 排序器在行为相关性和文本相关性两个维度同时实现 Pareto 前沿外移。全球 A/B 测试转化率提升 0.24%,在长尾 query 上收益最为显著。这一发现——专用微调小模型远优于通用大模型——对工业界选择 LLM 标注方案有直接参考价值。
PRECTR-V2 展示了 LLM 蒸馏的实践路径:从 Qwen-7B 教师模型蒸馏到仅约 200 万参数的 3 层轻量 Transformer 编码器(BERT-base 的 1/55),在闲鱼搜索排序中实现 GMV +3.18%。何向南团队的另一项工作 Turning Semantics into Topology 提出将 LLM 的语义推理能力转化为图拓扑结构,为协同过滤图注入语义信息,Recall@20 最高提升 22%。这些工作共同描绘了 LLM 融合推荐的多条实用路径:伪标签生成、verbalization 优化、相关性标注、知识蒸馏和语义拓扑增强。
推荐系统效率优化:从粗粒度压缩到精细化工程
效率优化是推荐系统永恒的主题,本周多篇论文在长序列建模、模型推理加速和向量检索优化三个方向展示了新进展。
HiSAC 在超长序列建模方向迈出了重要一步。长序列建模从 DIN(2017,百级别)、SIM(2020,五万级别)到 TWIN(2023,快手部署),经历了从注意力池化到两阶段检索的演进。但 SIM/TWIN 等方法的检索阶段采用固定粒度压缩,不考虑用户个性化。HiSAC 的突破在于引入生成式推荐领域的 Semantic ID 技术来构建个性化的层次化压缩——用多模态 RQ-VAE 编码用户行为序列,通过层次化投票机制稀疏激活个性化兴趣代理(interest-agent,约 200 个/用户),soft-routing attention 生成紧凑表示。复杂度从 O(NM) 降至 O(NK)+O(KM),FLOP 减少约 72%,端到端延迟降低 40%。淘宝首页部署后 CTR +1.65%、订单量 +2.56%。值得注意的是,解耦设计(冻结语义 embedding 用于路由 + 可训练 embedding 用于聚合)是性能的最大影响因子——使用单一共享 embedding 导致 AUC 下降 1.5 个点。
MaRI 将计算机视觉领域的结构重参数化(源自 RepVGG,2021)首次系统性应用于推荐排序模型。核心洞察是:排序模型推理中用户侧特征在同一请求内对所有候选 item 相同,存在 batch 维度的冗余计算。MaRI 通过数学等价变换将用户、物品、交叉特征计算解耦,推迟用户特征的复制操作。与知识蒸馏、剪枝等有损加速方法不同,MaRI 是精确的数学等价变换,实现零精度损失。快手粗排阶段推理加速 1.32 倍,延迟降低 2.2%,硬件资源节省 5.9%,核心业务指标无统计显著差异。该工作出自快手盖坤团队,目前标注为 "work in progress"。
昆士兰大学 Guido Zuccon 团队的 Where Relevance Emerges 为 LLM 重排效率优化提供了理论基础。通过逐层分析 LoRA 微调后的 LLM(Mistral-7B、LLaMA3.1-8B 等),发现相关性信号呈"钟形曲线"分布——集中在中间层而非最后一层。基于这一发现提出的 Selective-ICR 策略可降低 30%-50% 推理延迟且不损失效果,小模型(0.6B)在推理密集型基准(BRIGHT)上甚至超越现有生成方法。
重点论文解读
STATIC: 生成式检索的约束解码瓶颈终结者
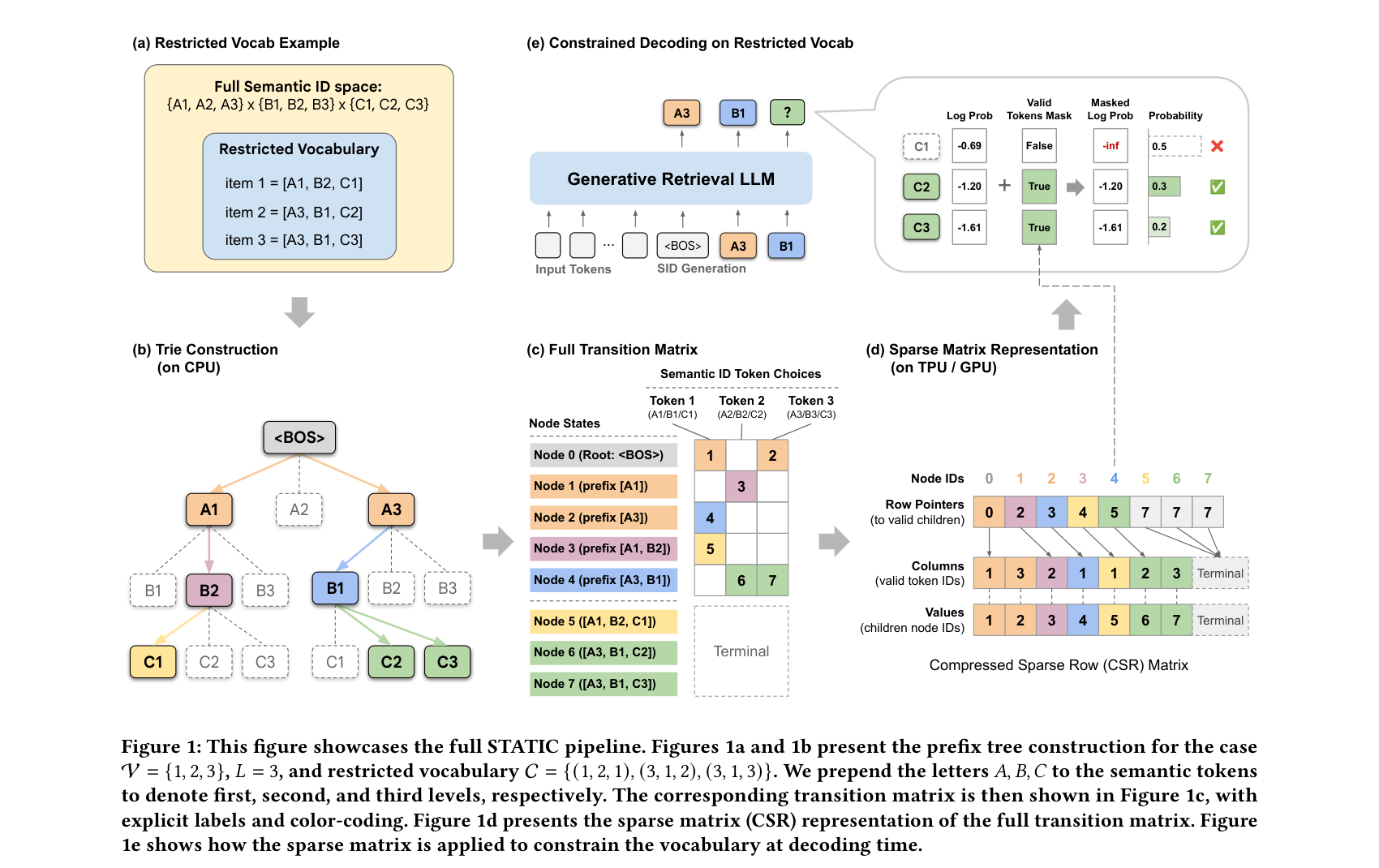
生成式检索系统在工业部署中面临一个尴尬的矛盾:模型理论上可以生成任意 Semantic ID 序列,但业务逻辑往往要求输出严格限制在特定子集内——例如只推荐 7 天内上传的新鲜视频,或只推荐特定品类的商品。传统的 Trie 约束解码在 CPU 上实现,但 TPU/GPU 架构的大规模并行能力无法处理 Trie 的不规则树遍历,成为生成式推荐工程化的关键瓶颈。
STATIC(Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding)的解决方案优雅而高效:将前缀树扁平化为静态 CSR 稀疏矩阵,设计无分支的向量化节点转换核心(VNTK),利用 DynamicSlice 原语实现 O(1) 定长提取。对于前 2 层(分支因子最大),使用 bit-packed 稠密布尔张量实现 O(1) 查找;更深层使用"投机性切片"(speculative slice)提取固定数量的条目。整个约束解码的 I/O 复杂度为 O(1)(关于约束集大小),而此前最优的 PPV 方法为 O(log|C|)。
实验数据令人印象深刻:相比 CPU Trie 实现 948 倍加速,相比硬件加速的 PPV 基线 47-1033 倍加速,延迟仅 0.033ms/step(推理时间的 0.25%)。约束集从 10^5 扩展到 10^8,STATIC 保持近乎恒定的延迟——这意味着它可以轻松处理从百万到十亿级别的候选库约束。YouTube 的线上 A/B 测试(beam size=70,SID 长度 L=8,token 词表 |V|=2048)显示 7 天新鲜视频观看量 +5.1%(95% CI: [5.0%, 5.2%]),CTR +0.15%,战略用户群满意度 +0.15%。
与 TIGER 的开创性工作和 RelayGR 的长序列优化相比,STATIC 填补的是 GR 系统从"能生成"到"能受控生成"的工程鸿沟。来自 Google Ed Chi 团队的这项工作,延续了该团队在生成式检索/推荐领域的开创性贡献。
SIGMA: 从单任务到多任务的生成式推荐范式跃迁
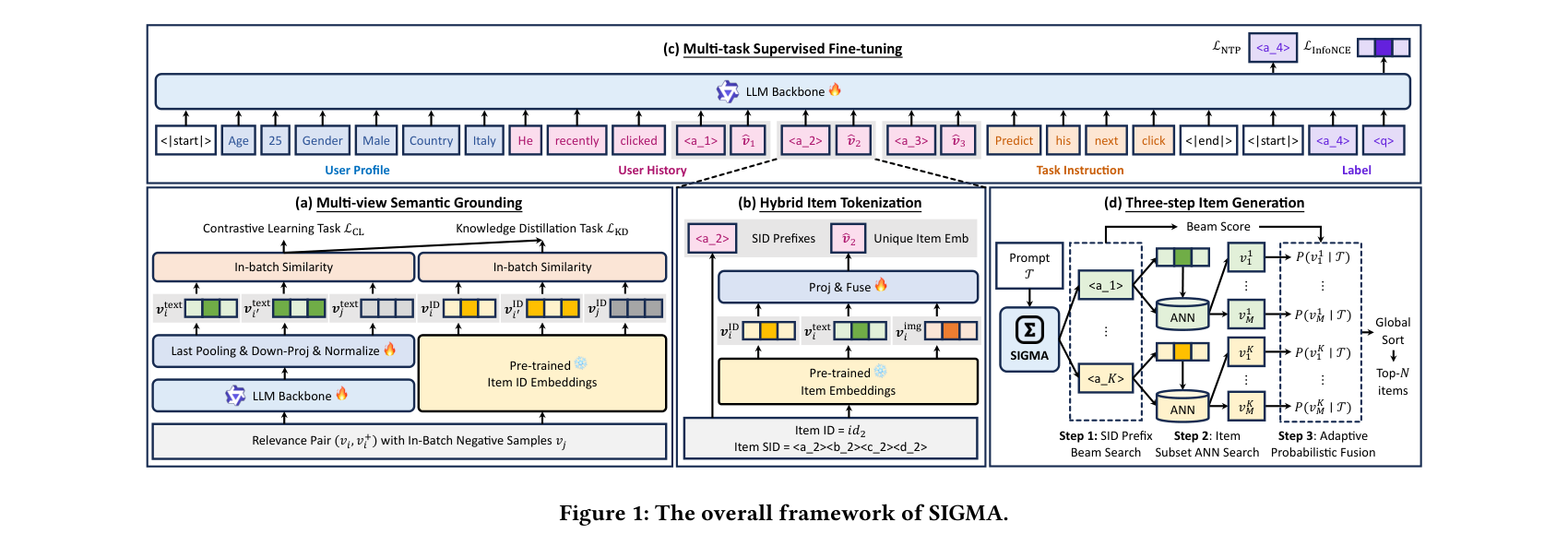
SIGMA(Semantic-Grounded Instruction-Driven Generative Multi-Task Recommender)在 AliExpress 的部署代表了生成式推荐的一个重要演进方向:从单一排序任务扩展到多任务统一框架。该工作已被 SIGIR 2026 接收。
多视角语义锚定是 SIGMA 的核心创新。它通过四种对齐方式——语义对齐(搜索日志中的 query-item 高点击关联)、视觉对齐(多模态模型配对相同风格特征的 item)、知识对齐(世界知识与主题 item 关联)和协同对齐(session 内共现 item)——将物品锚定到统一的语义潜空间。训练使用 InfoNCE Loss + batch 内负样本做对比学习,硬负样本规模达 100K(batch-shared),知识蒸馏将协同信号从已有 ID embedding 迁移。与 TIGER 仅使用内容 embedding 做 RQ-VAE 不同,SIGMA 的潜空间同时编码了语义和协同信号。与 HSTU 的纯行为序列建模不同,SIGMA 通过指令驱动实现了任务级别的灵活性。
混合 Item Tokenization 结合 SID 前缀 token(从 RQ-VAE 量化语义 embedding 得到,codebook 256x4)和 ID token(索引融合后的 item 表示),最优配置为 SID1ID→SID1ID。自适应概率融合(APF)机制根据 top-K beam score 的标准差调制输出分布——受约束任务锐化、探索性任务展平。线上 A/B 测试(5% 流量,两周)显示订单量 +2.80%、转化率 +3.84%、GMV +7.84%、购买品类广度 +2.47%。近线推理架构将结果异步填入 U2I 索引用于实时服务。
GPL: LLM 驱动的粗排偏差纠正
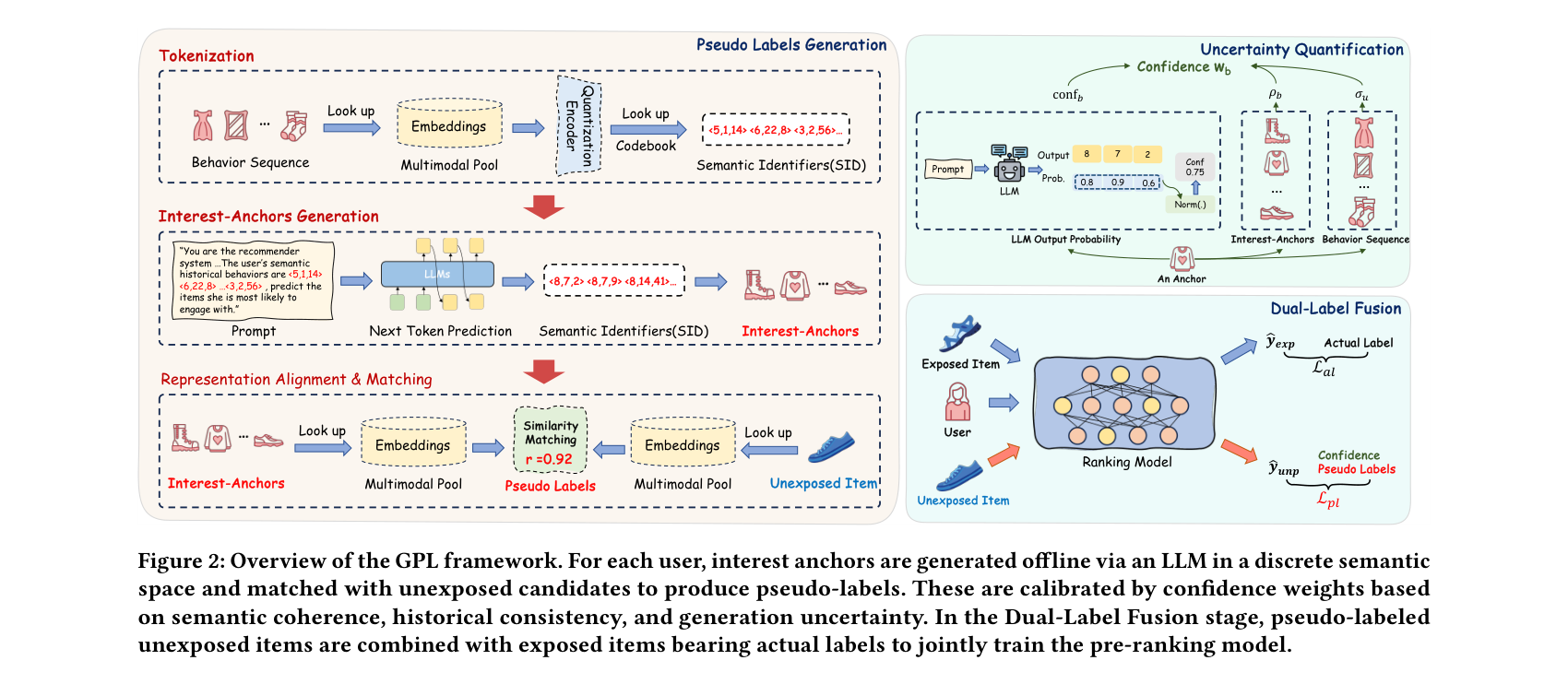
Generative Pseudo-Labeling 解决的是推荐系统全链路中一个长期被忽视但影响深远的问题:粗排阶段的样本选择偏差。粗排模型仅在曝光交互数据上训练,但在线服务时需要对所有召回候选(包括大量未曝光 item)打分。这种训练-服务分布偏移导致模型对未曝光 item 系统性低估,马太效应愈演愈烈。
GPL 的设计精妙之处在于将问题分解为两个子任务:用 LLM 预测用户可能感兴趣的"兴趣锚点",然后在冻结的语义空间中将锚点与候选匹配。微调的 Qwen2.5-0.5B(LoRA rank=8,可训练参数减少 99% 以上)从用户历史 SID 序列出发,通过层次化 beam search(宽度 B=32)解码多样化的 SID 候选。频率下采样 top 10% item 缓解流行度偏差,SID 存在率超过 98.5%。三维正交不确定性校准确保伪标签质量——语义离散度捕获认知不确定性,历史一致性衡量行为合理性,LLM 内在置信度(解码时的平均 log-probability)捕获偶然不确定性。
与传统的知识蒸馏方法(UKD, UECF)相比,GPL 在所有指标上全面领先:HR@3 0.5254 vs UECF 0.5216,AUC 0.7299 vs UECF 0.7246。消融实验揭示了一个重要发现:移除实际标签后 HR@3 从 0.5254 暴跌至 0.3687,说明真实监督信号仍不可或缺——伪标签是补充而非替代。淘宝线上 CTR +3.07%、IPV +3.53%、CTCVR +2.51%、停留时长 +2.16%,多样性提升超 35%(品类集中度从 70.80% 降至 45.91%)。全流程离线化(96 块 H20 GPU,6 小时/天),零在线延迟增加,LLM 推理调用减少 6 倍(用户级锚点生成而非 item 级)。
GR4AD: 广告场景下的生成式推荐全链路设计
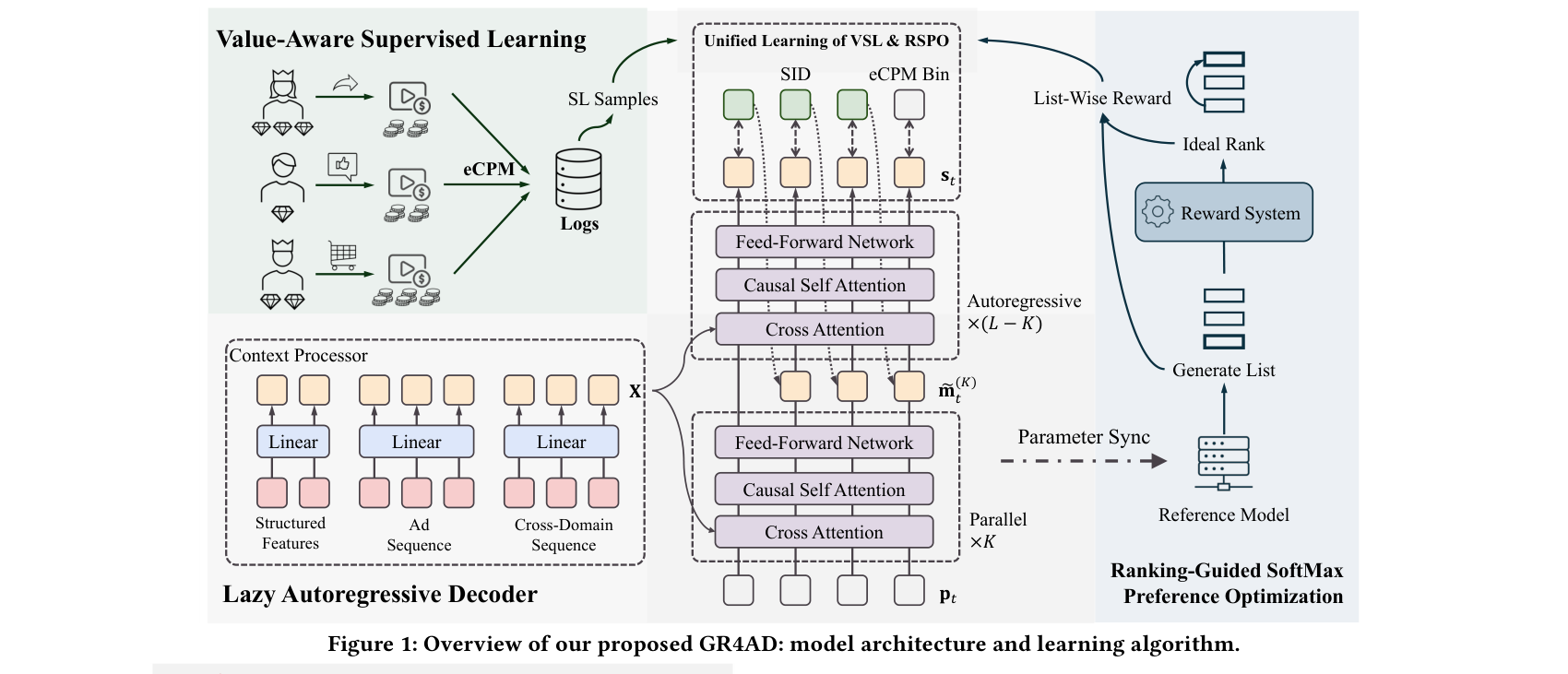
GR4AD 是首个在大规模广告场景全量部署的生成式推荐系统,全面替代了快手原有的 DLRM 广告检索栈。广告推荐相比内容推荐的独特挑战——价值建模(eCPM 优化)、严格延迟约束(<100ms)、中小广告主冷启动——驱动了一系列定制化设计。
UA-SID(统一广告语义 ID)基于 Qwen3-VL-7B 微调的多模态 LLM embedding,经指令微调和共现学习后 Photo-to-Photo Recall@1 从 0.769 提升至 0.896。MGMR(Multi-Granularity-Multi-Resolution)量化方案将碰撞率从 85.44% 降至 18.26%,codebook 利用率从 0.10‰ 提升至 0.34‰。LazyAR 解码器通过让前 6 层(共 9 层)跨解码步骤并行计算实现近 2 倍吞吐提升(QPS +117%),辅助 MTP loss 弥补了轻微质量损失。RSPO 以 eCPM 作为奖励信号优化列表级排序,创新引入基于 KL 散度阈值的参考可靠性门控。动态 Beam 服务在低峰期将 beam 扩大 60% 以提升质量。
各组件增量贡献清晰:UA-SID +1.92% 收入,VSL +2.80%,统一 VSL+RSPO +4.01%,DBS 额外 +0.31% 收入和 +20% QPS。Scaling law 实验显示模型规模(0.03B→0.32B,+2.13%→+4.43%)和推理规模(beam 128→1024,+2.33%→+4.21%)的收入增益均单调递增。工程优化组合——Beam-shared KV cache(+212.5% QPS)、TopK pre-cut(+184.8%)、FP8 低精度(+50.3%,收入影响仅 -0.1%)、结果缓存(+27.8%)——使单 L20 GPU 吞吐量达 500+ QPS,延迟 <100ms。实时闭环系统包含秒级 Item-SID 映射更新和持续在线学习。
工业实践
本周论文的工业部署密度在近期颇为罕见。11 篇有线上 A/B 测试验证的论文覆盖了推荐系统全链路:
召回/检索阶段:STATIC 在 YouTube 实现首个生产级约束生成式检索(新鲜视频 +5.1%,30 亿参数 Gemini 模型),GR4AD 在快手广告全量替代 DLRM 检索栈(收入 +4.2%,4 亿用户)。
粗排阶段:GPL 在淘宝通过 LLM 伪标签纠正粗排偏差(CTR +3.07%,多样性 +35%),MaRI 在快手通过结构重参数化实现零精度损失加速(1.32 倍,资源 -5.9%)。
精排阶段:SIGMA 在 AliExpress 部署多任务生成式排序(GMV +7.84%,SIGIR 2026),HiSAC 在淘宝首页通过层次化压缩建模万级序列(CTR +1.65%,订单 +2.56%),PRECTR-V2 在闲鱼统一相关性-CTR 建模(GMV +3.18%),Sequential Regression 在快手用残差量化预测广告 GMV(ADVV +4.19%)。
特征工程:FairFS 在华为广告平台纠正特征选择偏差(ECPM +1.35%,延迟 -20%),已被 WWW 2026 接收。
搜索排序:Scaling Search Relevance 在 Apple App Store 用 LLM 标注扩充训练数据(转化率 +0.24%,全球 A/B 测试)。
自动化建模:AgentLTV 在 VIVO 用 LLM Agent 自动化 LTV 预测流水线(误差率降低 41.26%),已投稿 KDD 2026 ADS Track。
工程层面的共性趋势:GR 系统普遍采用"离线构建 + 在线缓存"架构(HiSAC 离线构建 interest-agent,GPL 离线生成伪标签,SIGMA 近线推理填充 U2I 索引),LLM 的角色被严格限制在离线环节。用于在线推理的模型普遍在 0.1B-0.6B 量级(SIGMA 用 Qwen3-0.6B,GPL 用 Qwen2.5-0.5B,GR4AD 主力配置 0.16B),大模型仅用于离线标注或蒸馏。
值得关注的方向
Semantic ID 设计优化
本周有 5 篇论文直接涉及 SID 的设计改进(IntRR、SIGMA、HiSAC、TrieRec、Fine-grained Semantics Integration),表明 SID 作为 GR 系统的核心组件正在经历快速迭代。从 TIGER 的基础 RQ-VAE 到 SIGMA 的多视角语义锚定、IntRR 的动态重分配、HiSAC 的多模态层次化构建,SID 的设计空间远未被充分探索。值得跟踪 AliExpress、快手、YouTube 等平台的后续迭代,以及 SIGIR 2026(墨尔本,7 月)和 KDD 2026(济州岛,8 月)的相关投稿。快手的 DiffGRM(已被 WWW 2026 接收,4 月迪拜)用扩散模型替代自回归解码,也是一个值得关注的替代范式。
LLM 离线增强的规模化实践
GPL、Apple 和 PRECTR-V2 展示了"LLM 离线标注/蒸馏 + 轻量模型在线推理"的工业路径,但目前各家的实践仍相对孤立。如何将 LLM 离线增强系统化为通用的推荐系统基础设施——覆盖特征增强、标签生成、数据增广、模型蒸馏等多个环节——是下一步的关键问题。Netflix 的可学习 verbalization 暗示 LLM 融合还有大量未被探索的"中间地带",不仅限于离线标注和在线推理两个极端。
推荐系统的 Scaling Law
SIGMA(Qwen3-0.6B→4B 性能持续提升)和 GR4AD(0.03B→0.32B 收入单调递增,beam 128→1024 效果持续改善)在工业场景验证了 GR 系统的 scaling law。这与此前 HSTU 在 Meta 的观察一致。随着推荐系统从传统 DLRM(通常百万级参数)向 GR(亿级参数)演进,理解和利用推荐场景下的 scaling law 将成为核心竞争力。值得关注各平台在模型规模、数据规模和推理规模三个维度上的扩展实验。
本周论文速览
生成式推荐
SIGMA — AliExpress 多任务生成式推荐;多视角语义锚定 + 混合 item tokenization + 自适应概率融合;线上 GMV +7.84%,SIGIR 2026。
GR4AD — 快手广告生成式推荐全链路系统;UA-SID + LazyAR 解码器 + RSPO 列表级 RL + 动态 Beam 服务;线上收入 +4.2%,4 亿用户全量部署。
Vectorizing the Trie / STATIC — YouTube 生成式检索约束解码加速;Trie→CSR 稀疏矩阵向量化,948 倍加速;线上新鲜视频 +5.1%,首个生产级约束 GR,已开源。
IntRR — SID 重分配与长度压缩统一框架;递归分配网络 + UID 协同锚点,每 item 1 token;指标 +63.1%,训练吞吐 +75%。
TrieRec — Trie 感知 Transformer;两种位置编码注入 Trie 结构信息;多数据集平均提升 8.83%。
Fine-grained Semantics Integration — SID 语义初始化与对齐;SA-Init + TS-Align 解决 SID token embedding 随机初始化问题;可作为 RL 阶段更强 backbone。
LLM 融合推荐
Generative Pseudo-Labeling / GPL — LLM 驱动的粗排偏差纠正;语义 ID + 兴趣锚点 + 三维不确定性校准;淘宝线上 CTR +3.07%,多样性 +35%,零在线延迟。
From Logs to Language — Netflix 可学习 verbalization 框架;GRPO 强化学习优化日志到语言转换;Recall@1 +92.9%,Qwen-3 8B/32B。
PRECTR-V2 — 闲鱼统一相关性-CTR 框架;跨用户偏好挖掘 + 曝光偏差纠正 + Qwen-7B→200 万参数编码器蒸馏;线上 GMV +3.18%。
Scaling Search Relevance — Apple App Store LLM 标注增强搜索排序;微调 3B LLM 生成百万级相关性标签;全球 A/B 转化率 +0.24%。
Turning Semantics into Topology — LLM 语义转图拓扑增强协同过滤;构建 U-A-I 语义属性图;Recall@20 最高 +22%,冷启动显著改善。
Offline Reasoning — LLM 离线推理高效重排;构建物品 persona 表示,延迟降低 99.6%;延世大学 + NAVER 合作。
Where Relevance Emerges — LLM 重排内部注意力机制分析;"钟形曲线"分布发现 + Selective-ICR 策略;推理延迟降低 30%-50%。
效率优化
HiSAC — 淘宝超长序列层次化压缩建模;多模态 SID + 层次投票 + 软路由注意力;线上 CTR +1.65%,订单 +2.56%,FLOP -72%。
MaRI — 快手排序模型结构重参数化加速;用户侧计算解耦 + 图着色自动优化;零精度损失 1.32 倍加速,资源 -5.9%。
Sequential Regression / RQ-Reg — 快手残差量化连续值预测;RQ K-means + Scheduled Sampling + Rank-N-Contrast;线上 ADVV +4.19%。
AQR-HNSW — 密度感知量化 + 多阶段重排序加速 HNSW;QPS 2.5-3.3 倍提升,内存 -75%;DAC 2026。
Multi-Vector Index Compression — 多模态多向量检索压缩;注意力引导聚类(AGC);跨文本/视觉/视频模态验证。
其他方向
FairFS — 华为特征选择偏差纠正框架;层偏差/基线偏差/近似偏差三重修正;线上 ECPM +1.35%,延迟 -20%,WWW 2026。
AgentLTV — VIVO LLM Agent 自动化 LTV 预测;MCTS + 进化算法 + 多 LLM 协作;误差率降低 41.26%,投稿 KDD 2026。
E-MMKGR — 电商多模态知识图谱统一框架;GNN 传播 + KG 损失学习统一表示;推荐 Recall@10 +10.18%,搜索 MAP@10 +21.72%。
Learning to Collaborate via Structures — 联邦推荐聚类引导物品对齐;通信复杂度从 O(nd) 降至 O(n);ML-100K HR@5 +22.6%。
Towards Dynamic Dense Retrieval — 动态稠密检索路由策略;前缀调优 + 路由机制,仅 2% 参数实现跨域适应。